
自定义搜索引擎yacy
自定义搜索引擎解决了搜索范围的问题,多个网站聚合成一个引擎,相当于我这边筛选了一遍,再进行二次筛选,能提升效率
网站地址在programm able seach engine,添加搜索引擎
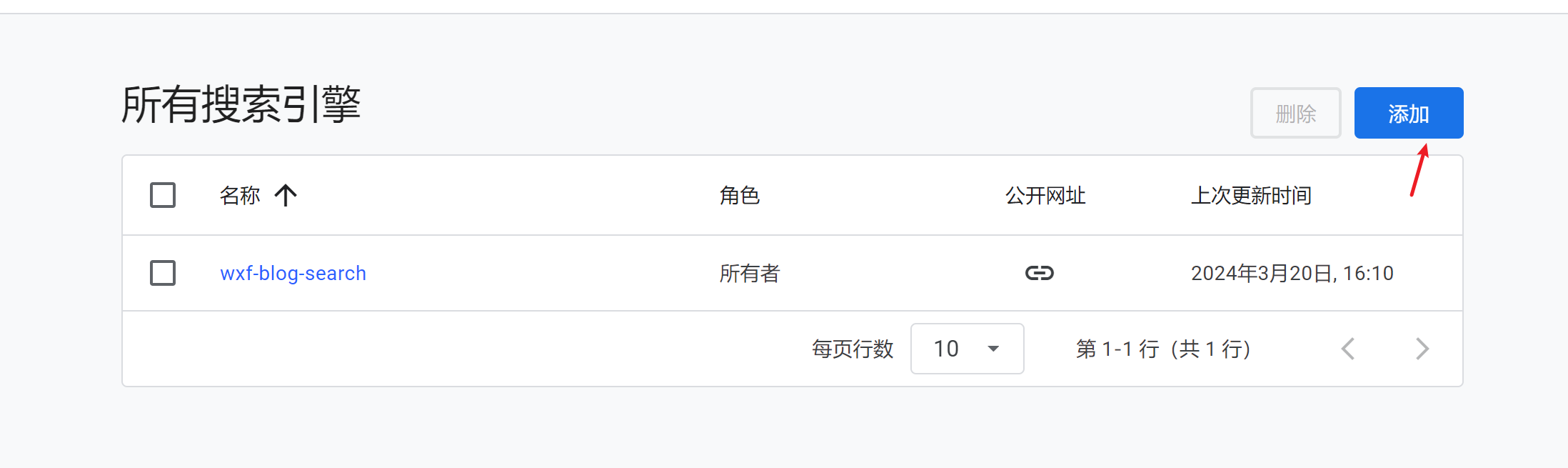
添加索引网站
点击进入实例,添加–>填网址
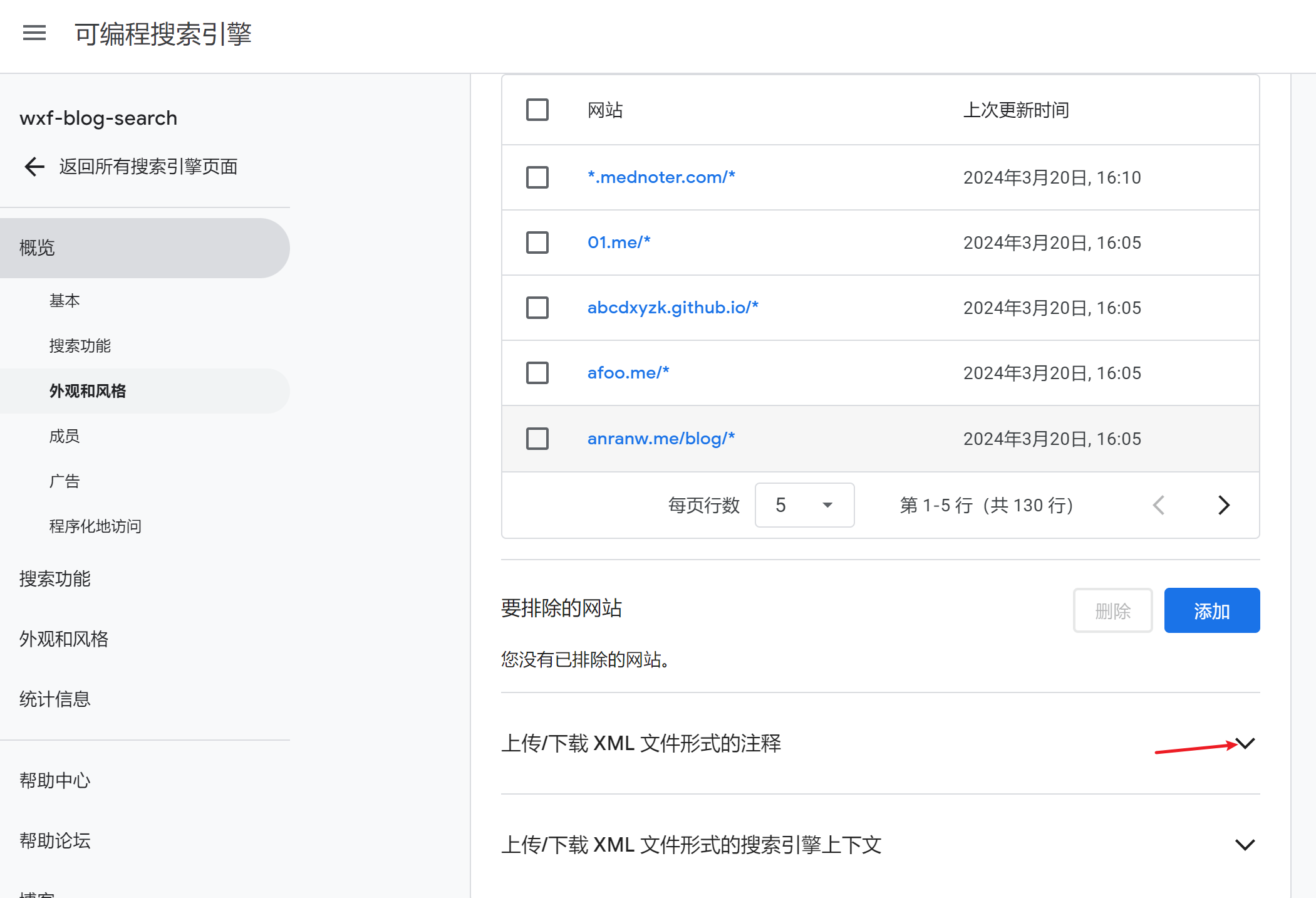 对网址格式做一说明,一般是"xxx.com/ * “,即该网站下所有页面
对网址格式做一说明,一般是"xxx.com/ * “,即该网站下所有页面
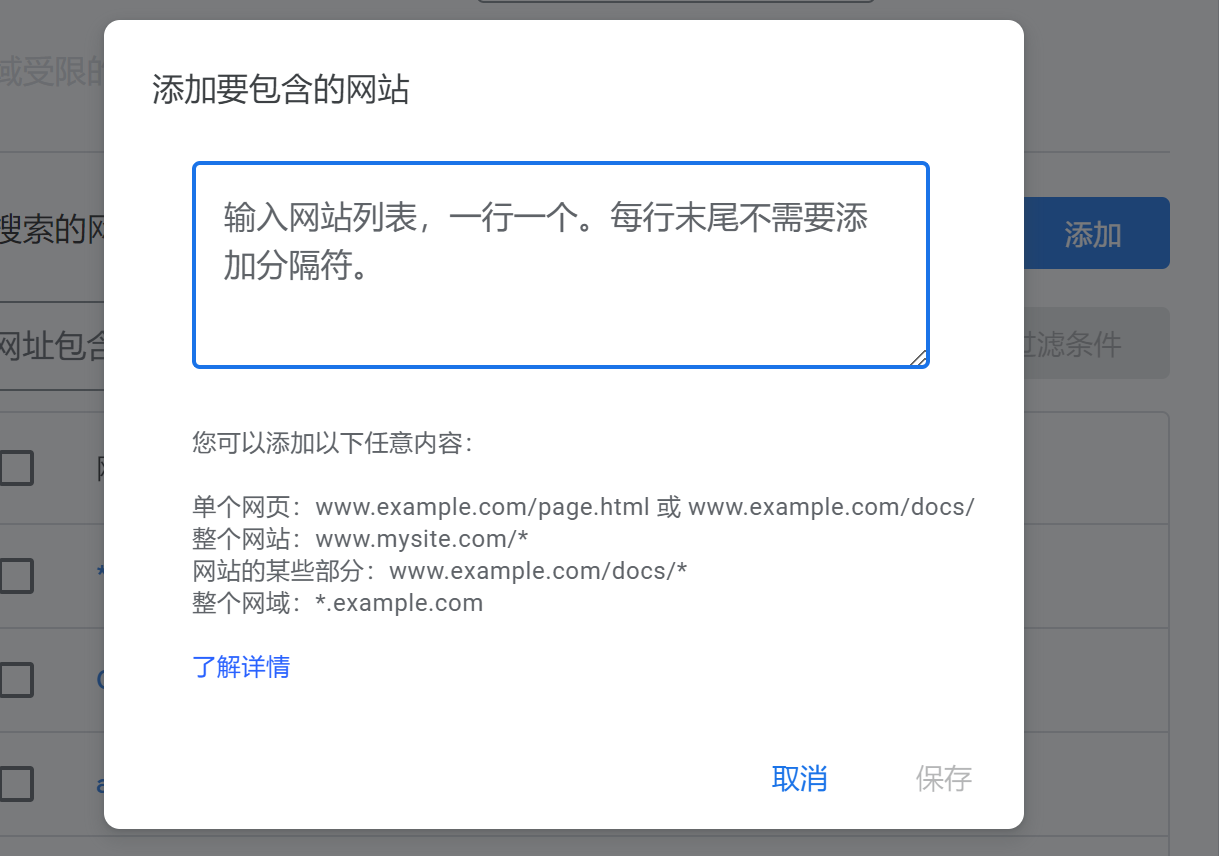 xml格式导入
xml格式导入
xml文件大概是这样,更改about和value值,就能批量添加地址了,当然,图形框也能批量添加
<Annotations>
<Annotation about="*.antirez.com/*" timestamp="0x0006140ea65e7149" score="1.0">
<Label name="_include_"/>
<AdditionalData attribute="original_url" value="http://antirez.com"/>
</Annotation>
<Annotation about="*.huoding.com/*" timestamp="0x0006140e7ab53ef5" score="1.0">
<Label name="_include_"/>
<AdditionalData attribute="original_url" value="https://huoding.com"/>
</Annotation>
</Annotations>
改外观
这样就行了
 最终所得网址如下
最终所得网址如下
qireader脚本
qireader是我看rss的工具,导出opml文件,里面包含了订阅所有博客的网址,我写了个python脚本把网址转化为xml格式,以便导入
# 描述: 这是一个Python脚本,用于构建google ces的annoation格式文本,达到批量导入博客,用于检索的目的
# 作者: wxf
# 版本: 1.0
# 生成日期: 2024/03/20
# 最后修改日期: 2024/03/20
import re
import os
import subprocess
# 从本地文件读取文本
file_path = 'QiReader subscriptions - Wed Mar 20 2024.opml'
with open(file_path, "r", encoding='utf-8') as file:
text = file.read()
# 使用正则表达式提取htmlUrl
html_urls = re.findall(r'htmlUrl="(.*?)"', text)
url = []
with open("tmp_urls.txt", "w") as file:
for url in html_urls:
file.write(url + "\n")
tmp_flit_urls = []
## 替换尾部//为/
grep_command = ['grep', '//$', 'tmp_urls.txt']
awk_command = ['awk', '-i','inplace','{sub(/\/\/$/, \"/\")}1', 'tmp_urls.txt']
grep_rlt = subprocess.run(grep_command, capture_output=True, text=True)
file_list = grep_rlt.stdout.splitlines()
for file in file_list:
subprocess.run(awk_command,text=True)
## 替换https: xx为空格
substring = ["http://","https://","http://www.","https://www.","www."]
for url in html_urls:
for sub_str in substring:
if sub_str in url:
url = url.replace(sub_str, "",1)
if url.endswith("/"):
tmp_flit_urls.append(url + "*")
else:
tmp_flit_urls.append(url + "/*")
# 输出处理后的htmlUrl列表到文件
with open("tmp_flit_urls.txt", "w") as file:
for url in tmp_flit_urls:
file.write(url + "\n")
# 从txt文本中读取网址列表
about_list = []
value_list = []
# 从xx.txt文件中读取内容并写入about_list列表
with open("tmp_flit_urls.txt", "r") as file:
for line in file:
about_list.append(line.strip())
# 从tmp_urls.txt文件中读取内容并写入value_list列表
with open("tmp_urls.txt", "r") as file:
for line in file:
value_list.append(line.strip())
# 原始标签内容
original_text = """
<Annotation about="*.huoding.com/*" timestamp="0x0006140e7ab53ef5" score="1.0">
<Label name="_include_"/>
<AdditionalData attribute="original_url" value="https://huoding.com"/>
</Annotation>
"""
# 生成替换后的格式化文本
formatted_texts = []
for about, value in zip(about_list, value_list):
replaced_text = original_text.replace("*.huoding.com/*", about)
replaced_text = replaced_text.replace("https://huoding.com", value)
formatted_texts.append(replaced_text)
# 输出生成的格式化文本到文件
with open("annotations.xml", "w") as file:
file.write("<Annotations>\n")
for text in formatted_texts:
file.write(text + "\n")
file.write("</Annotations>")
# 删除含有tmp字符的文件
files = os.listdir(".")
for file_name in files:
if "tmp" in file_name:
file_path = os.path.join(".", file_name)
os.remove(file_path)
print(f"文件 {file_name} 已成功删除。")
‘QiReader subscriptions - Wed Mar 20 2024.opml’这个文件和脚本放同一文件夹下,执行完毕后会得到一个annotations.xml的文件,直接导入即可,见“添加索引网站”小节
<Annotations>
<Annotation about="antirez.com/*" timestamp="0x0006140e7ab53ef5" score="1.0">
<Label name="_include_"/>
<AdditionalData attribute="original_url" value="http://antirez.com"/>
</Annotation>
<Annotation about="righto.com/*" timestamp="0x0006140e7ab53ef5" score="1.0">
<Label name="_include_"/>
<AdditionalData attribute="original_url" value="http://www.righto.com/"/>
</Annotation>
<Annotation about="lijiaocn.com/*" timestamp="0x0006140e7ab53ef5" score="1.0">
<AdditionalData attribute="original_url" value="https://emacsguru.wordpress.com"/>
</Annotation>
... 太长不看
</Annotation>
效果评估
按理说能检索到我写的网址的所有网页
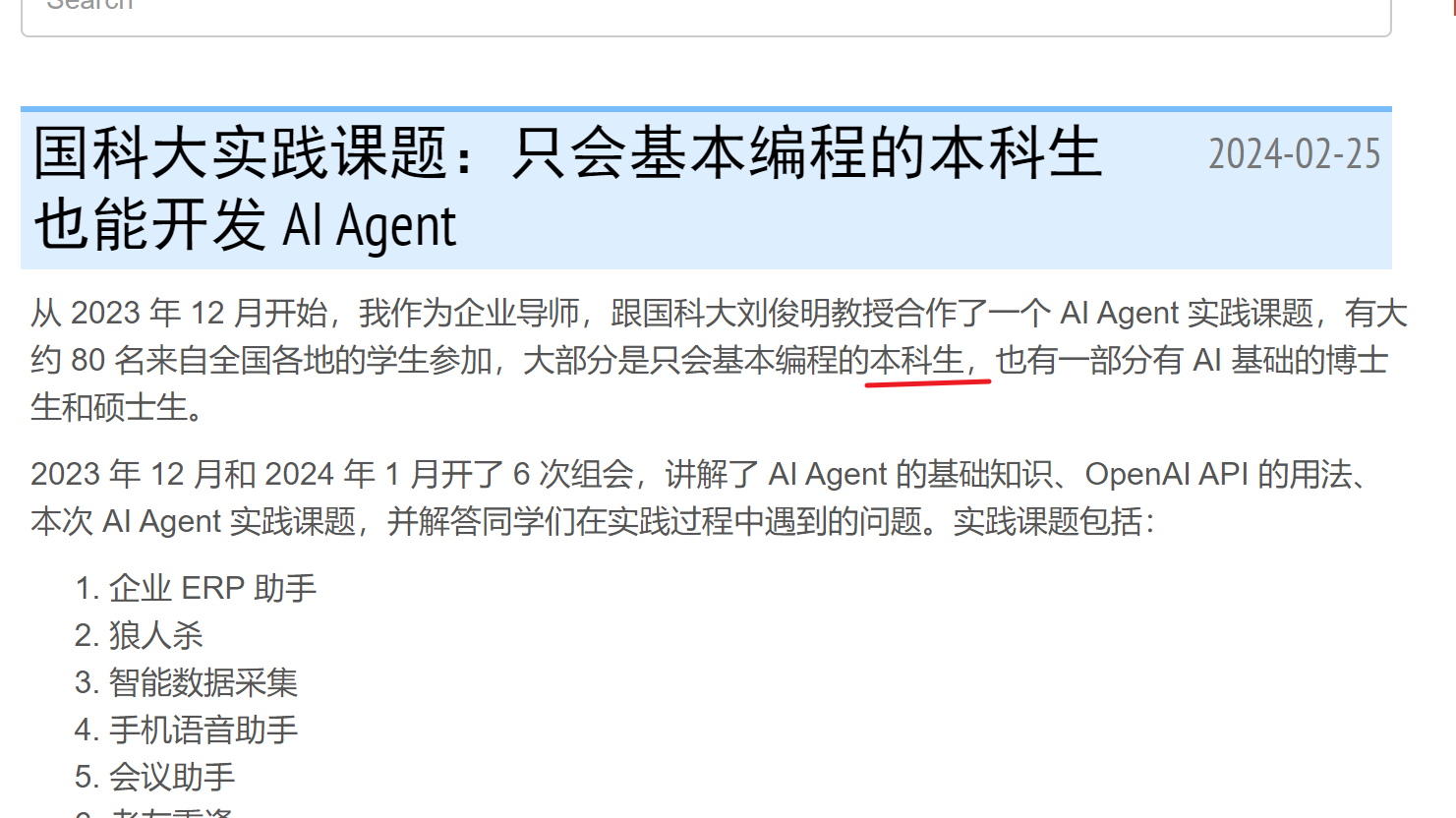
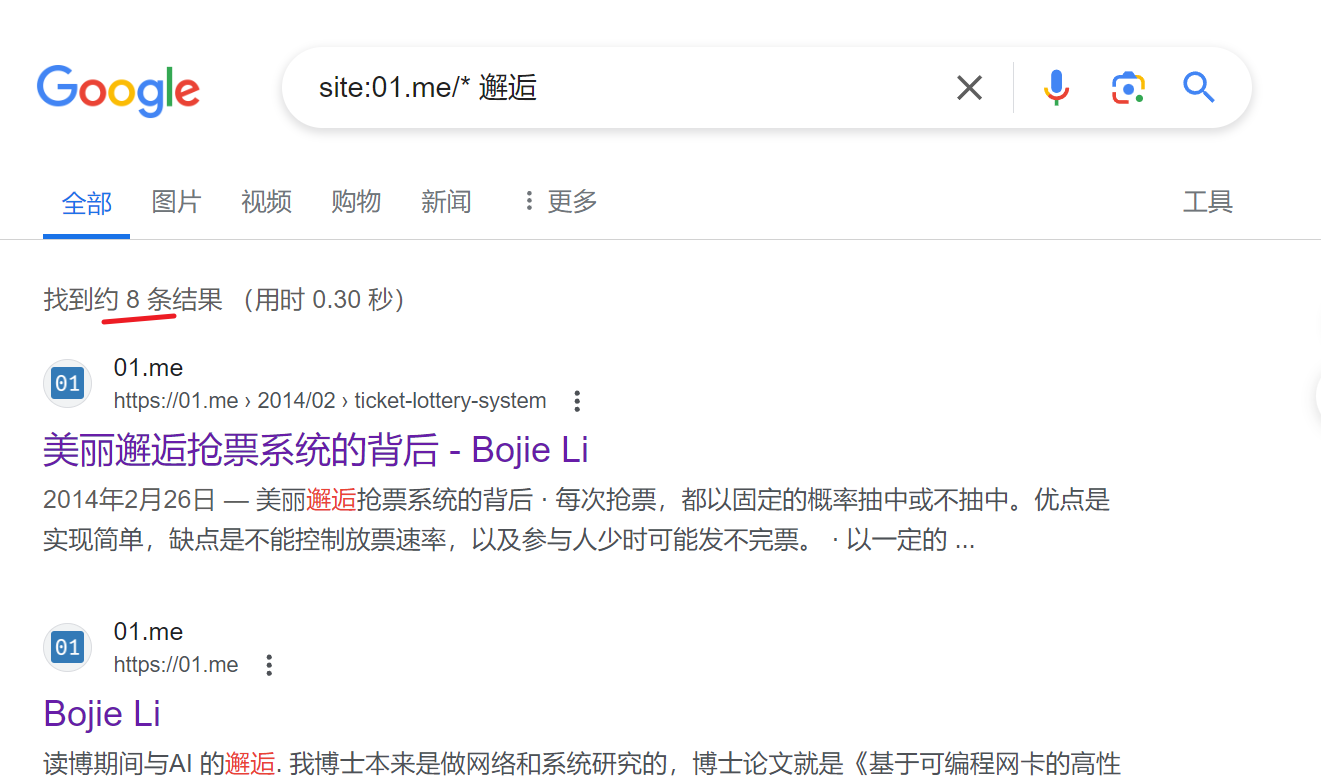
以01.me为例,选取关键词"本科生”、“邂逅”、“创业”,分别在google、ces引擎搜索,结果如下:
原博客

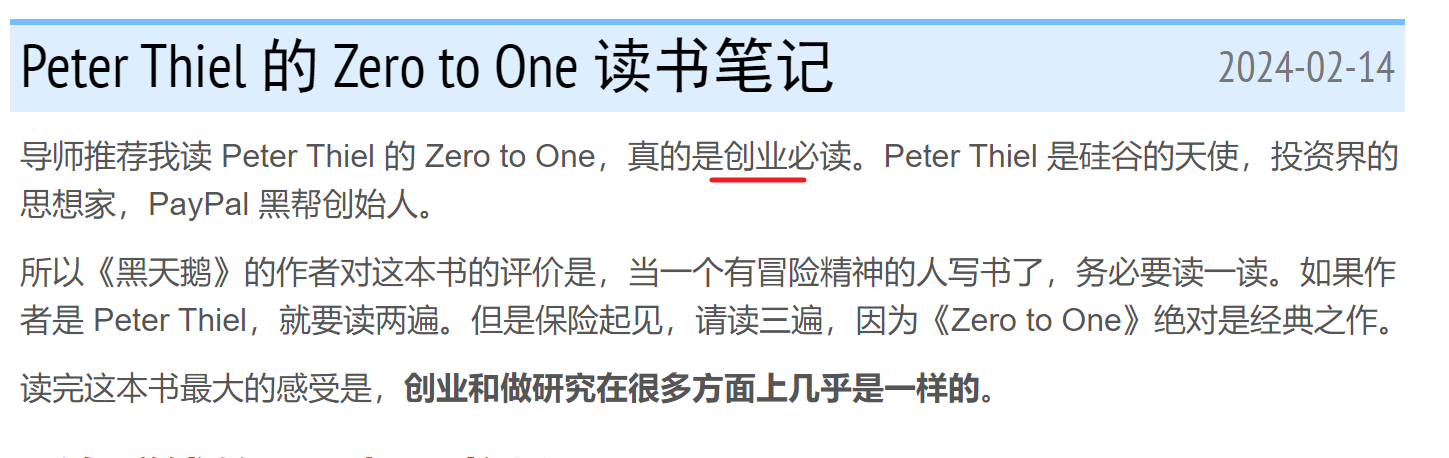 google语法搜索
google语法搜索
大差不差,inurl更深入
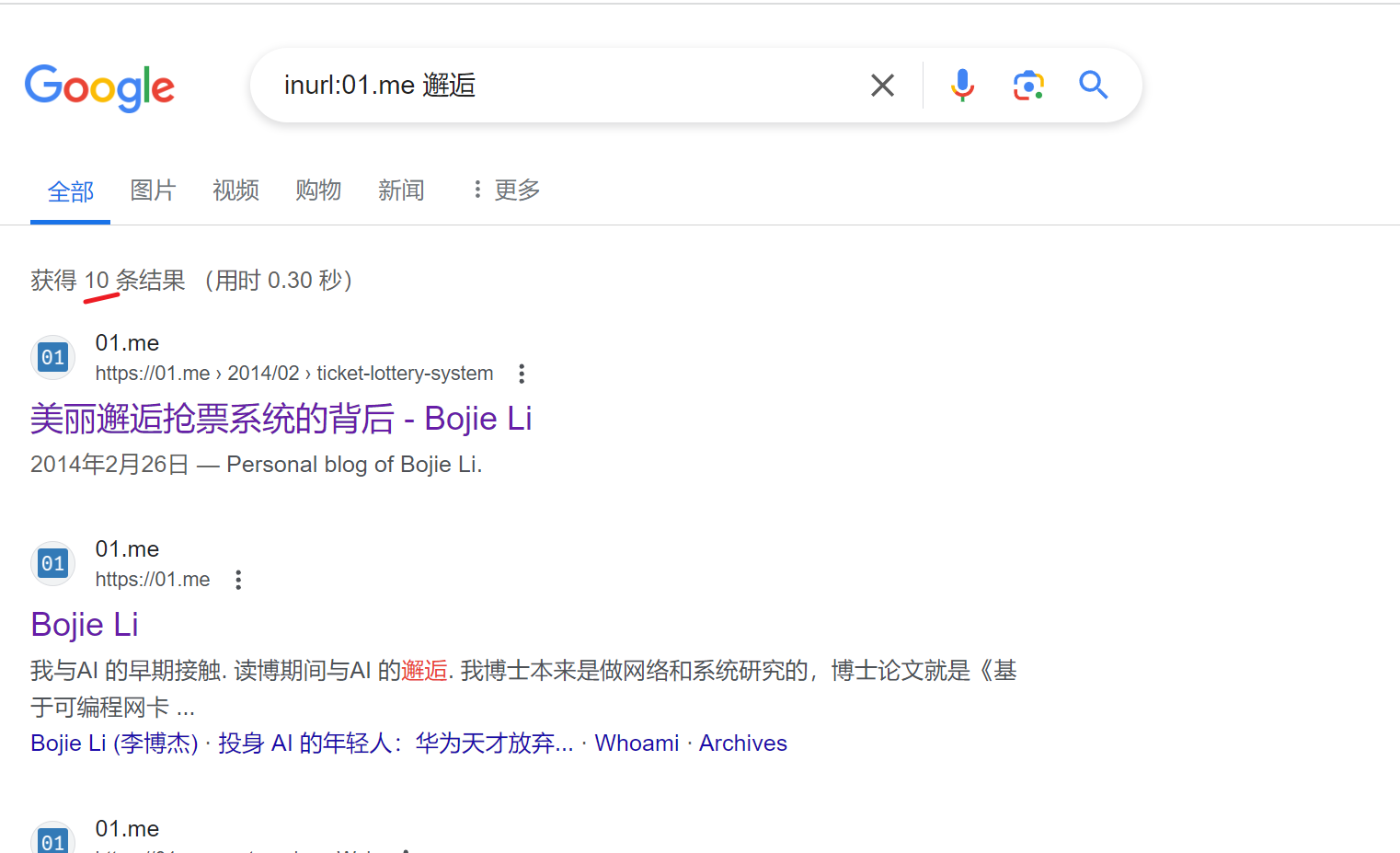
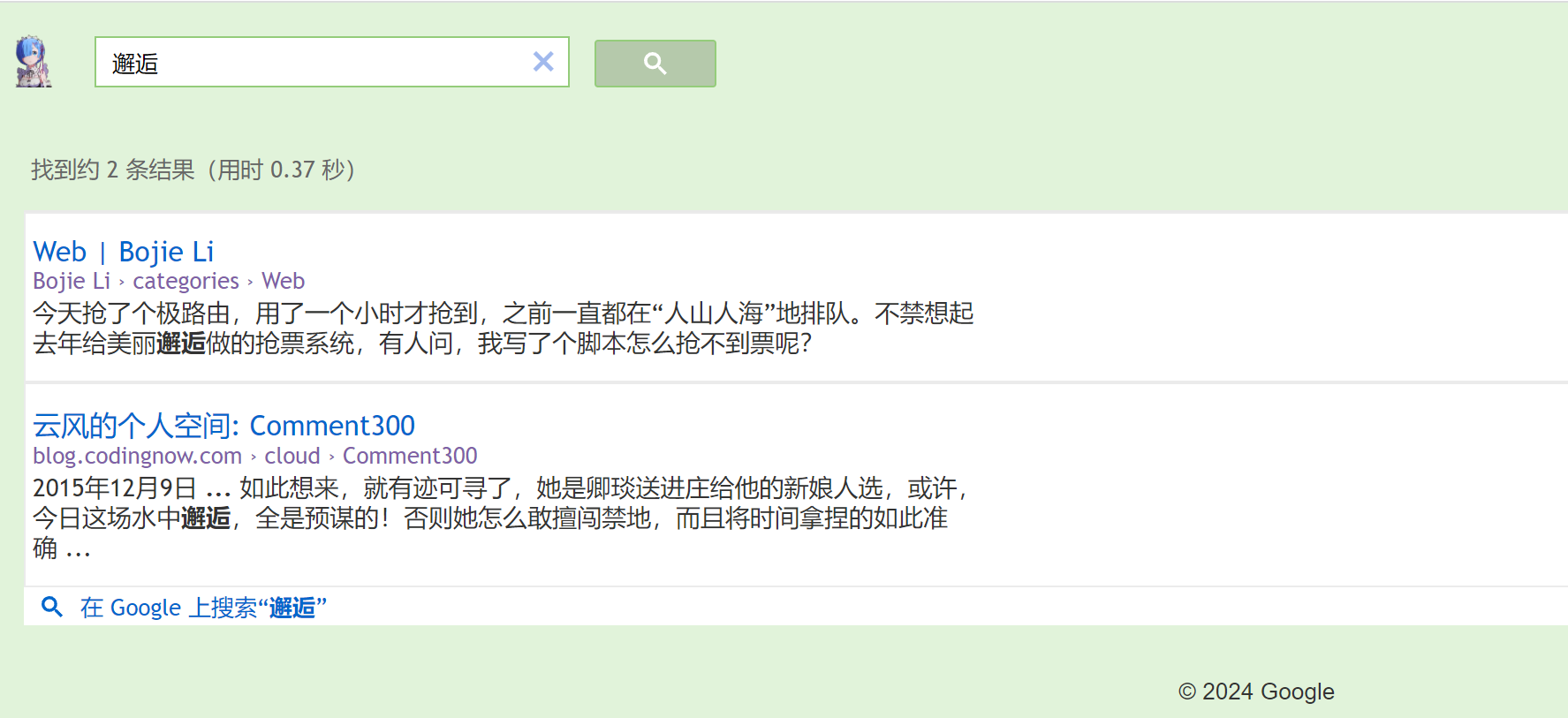
 ces搜索
ces搜索
很垃圾啊,也就是说之前的工作白做了
继续探索
这个时候得搞清楚搜索引擎的工作原理,可以认为搜索引擎是以某种数据形式拆解网页,结合算法+算力,实现大量网页的索引
一个点是爬取相关网站的所有内容,以特定形式存储,另一个点是算法、分布式
我的目标是搜索特定网站内容,有两种解决方案
第一种是用google 的api,拿到数据后自建页面排序展示,工作量巨大
第二种如下\
> 提问:开源检索网络的网站
> 回答:
开源检索网络的网站中,一个备受推荐的是**YaCy**。YaCy是一个去中心化的搜索引擎,由网络上的众多参与者共同维护。它的目标是创建一个公开、透明且不受单一实体控制的搜索引擎。
### YaCy的特点包括:
- **去中心化**:YaCy利用P2P技术,使搜索索引分布在全球范围内的参与者之间,而不是存储在中心服务器上。
- **隐私保护**:由于其去中心化的特性,YaCy提供了较高的匿名性和隐私保护。用户的搜索请求不会被跟踪。
- **自主爬虫**:YaCy拥有自己的网络爬虫技术,用户可以自定义爬虫的行为,包括要爬取的网站和内容。
- **开源**:YaCy是完全开源的,这意味着任何人都可以查看其代码、进行修改或贡献。
YaCy适合那些希望建立自己的搜索引擎、研究搜索技术或者关心隐私保护的用户和开发者。它可以被部署为个人的搜索门户,也可以作为一个组织内部的搜索解决方案。YaCy的开源性质和去中心化架构为搜索引擎领域提供了一个独特且有力的选择。
yacy
docker run -d --name yacy_search_server -p 8090:8090 -p 8443:8443 -v /d/local_data/yacy:/opt/yacy_search_server/DATA --restart unless-stopped --log-opt max-size=200m --log-opt max-file=2 yacy/yacy_search_server:latest
如此,在浏览器的8090端口就能访问yacy服务了,数据映射在本地"d:/local_data/yacy/“目录
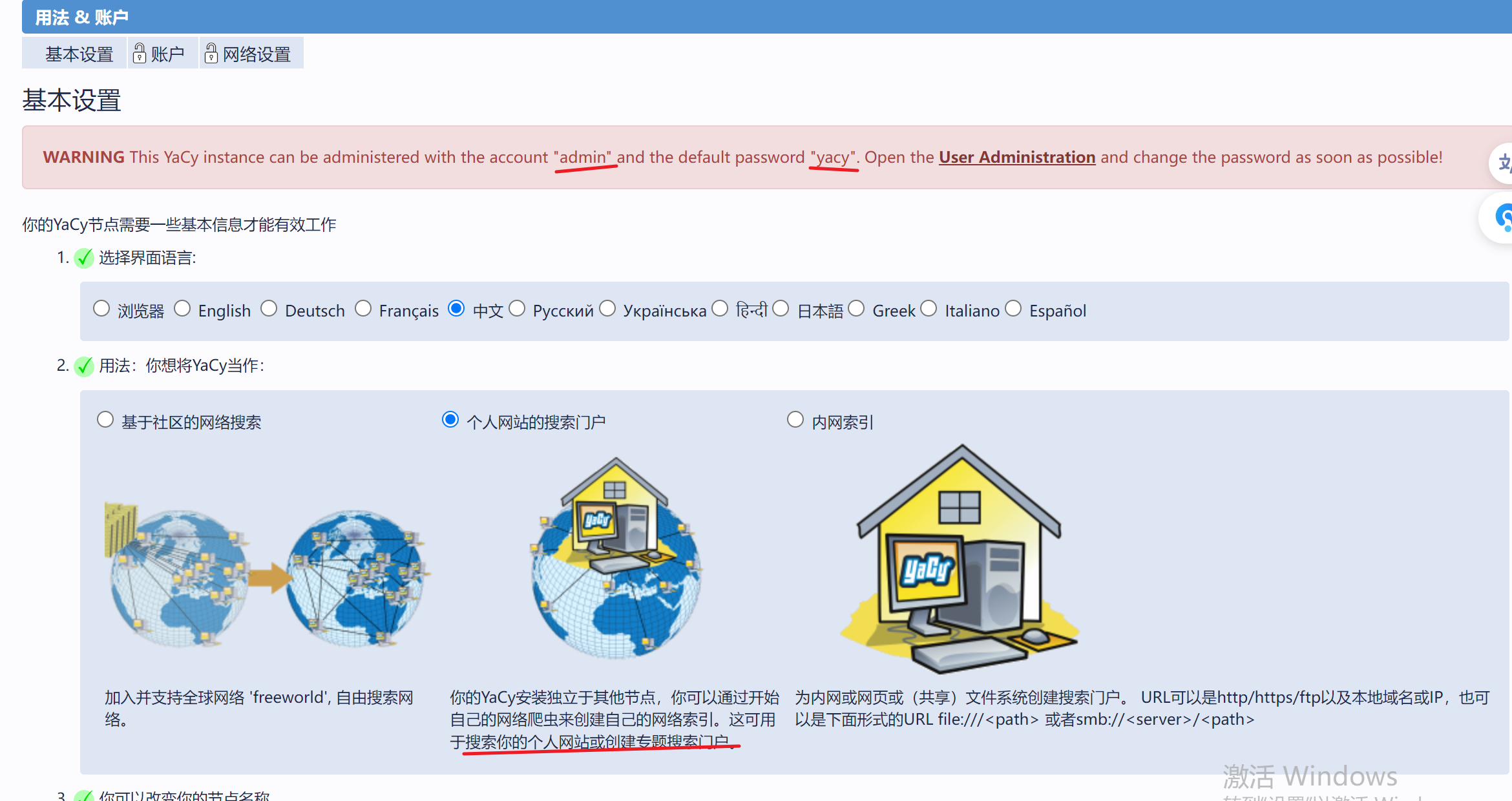
账号登录,选择个人网站搜索
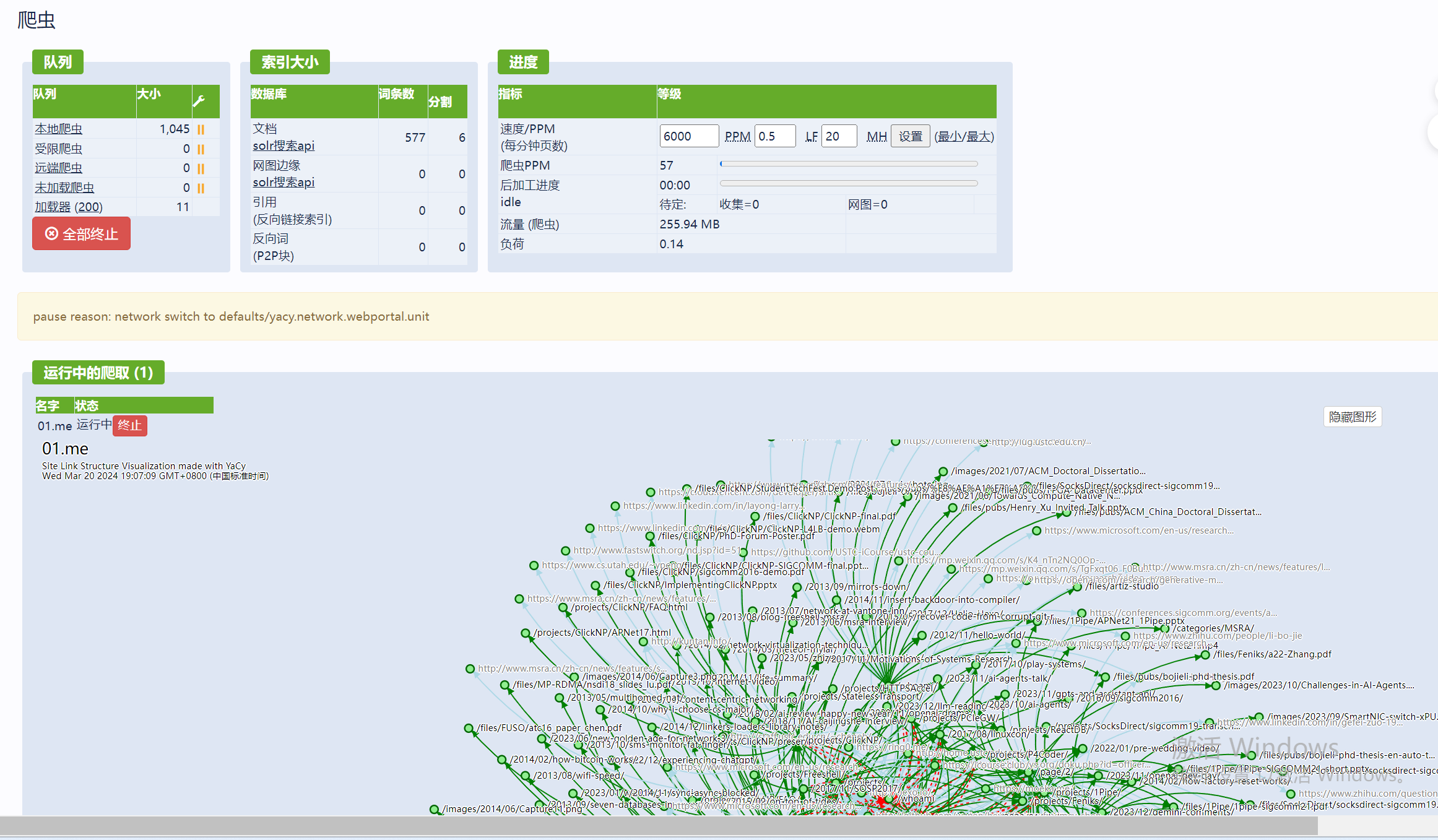
 我爬取了"https://01.me”,注:限制起始域,只爬取01.me的所有内容;文档内容限制(MIME)为只匹配"text/html",只拿到文本即可
我爬取了"https://01.me”,注:限制起始域,只爬取01.me的所有内容;文档内容限制(MIME)为只匹配"text/html",只拿到文本即可
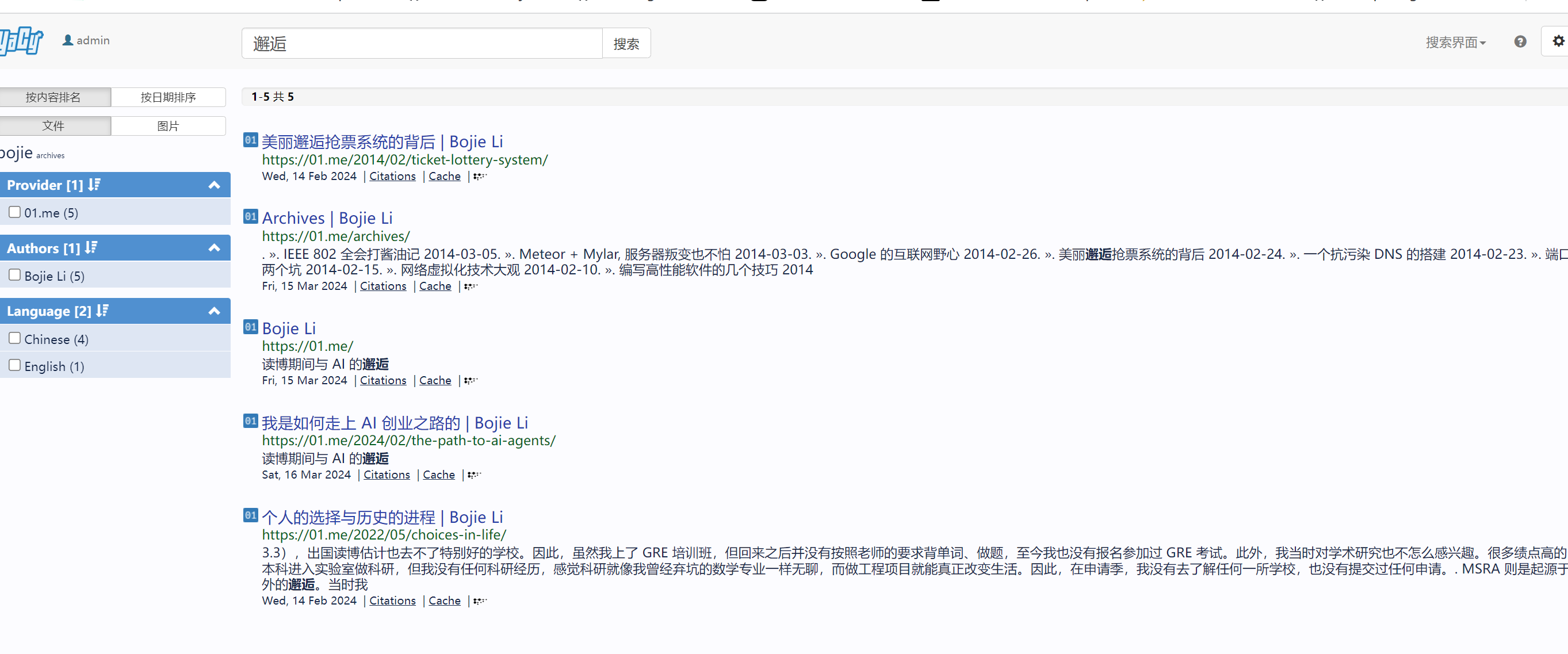
 搜索效果如下,比google ces强多了,当然,只要优化爬虫策略,应该能检索到更多结果
搜索效果如下,比google ces强多了,当然,只要优化爬虫策略,应该能检索到更多结果
总结
目的是自定义搜索引擎,任务算是完成了,回溯一下整个过程,关键点在搜索效果的对比验证,写python脚本(借助juchats),juchats给出的提示(跟我的提问方式也有关系)
对于有全局视野的人来说,ai无疑能大大提高生产力